gpu.cpp
Simple & Portable GPU Compute
using WebGPU
using WebGPU
@austinvhuang
|
Answer.AI

for personal, local-first GPU compute.
Why Local GPU Compute Matters
- Scale. The world's personal devices as a distributed GPU cluster.
- Ownership. Control + implementation stability.
- Robustness. Decorrelate failure modes of AI systems.
- Minimize Footprint. Privacy, security, legal compliance.
- Embodied Computation. AR, robotics => +bandwidth, -latency, +privacy.
Impediments to local GPU Development
- Personal devices are heterogeneous while tooling is vendor and hardware-specific
- GPU access is intermediated through task-specific engines/frameworks/runtimes
- Direct access to GPU (eg vulkan or webgpu) is optimized for large-scale framework implementations
- Complex builds (cmake / Dawn etc)
Launching a compute kernel with Vulkan
~ 800 lines of code

Engines / Frameworks / Runtimes
Goal: GPU as "just" programming
- No custom tooling - clang is all you need
- General purpose - not a task-specific engine/framework
- Low level expressiveness - can we express the control we'd want in CUDA, ROCm, Vulkan?
- Portable - not coupled to any specific vendor, operating system, hardware
- Simple to Embed - easy to drop in GPU code into projects small and large
- Widely Supported - build on foundation with high Prob(broad adoption)
gpu.cpp
A library for simple, portable low-level GPU computation using WebGPU

Native WebGPU Implementations
 (the "easy" API ~ 400 LoC)
(the "easy" API ~ 400 LoC)
3 Main Aspects of GPU Compute
- The GPU code that runs on the device implementing the compute operation (WGSL).
- Ahead-of-time code that runs on the CPU that sets up the GPU computation by allocating and preparing resources (C++).
- Hot path code that runs on the host which asynchronously dispatches the GPU computation, with minimal I/O or compute overhead (C++).
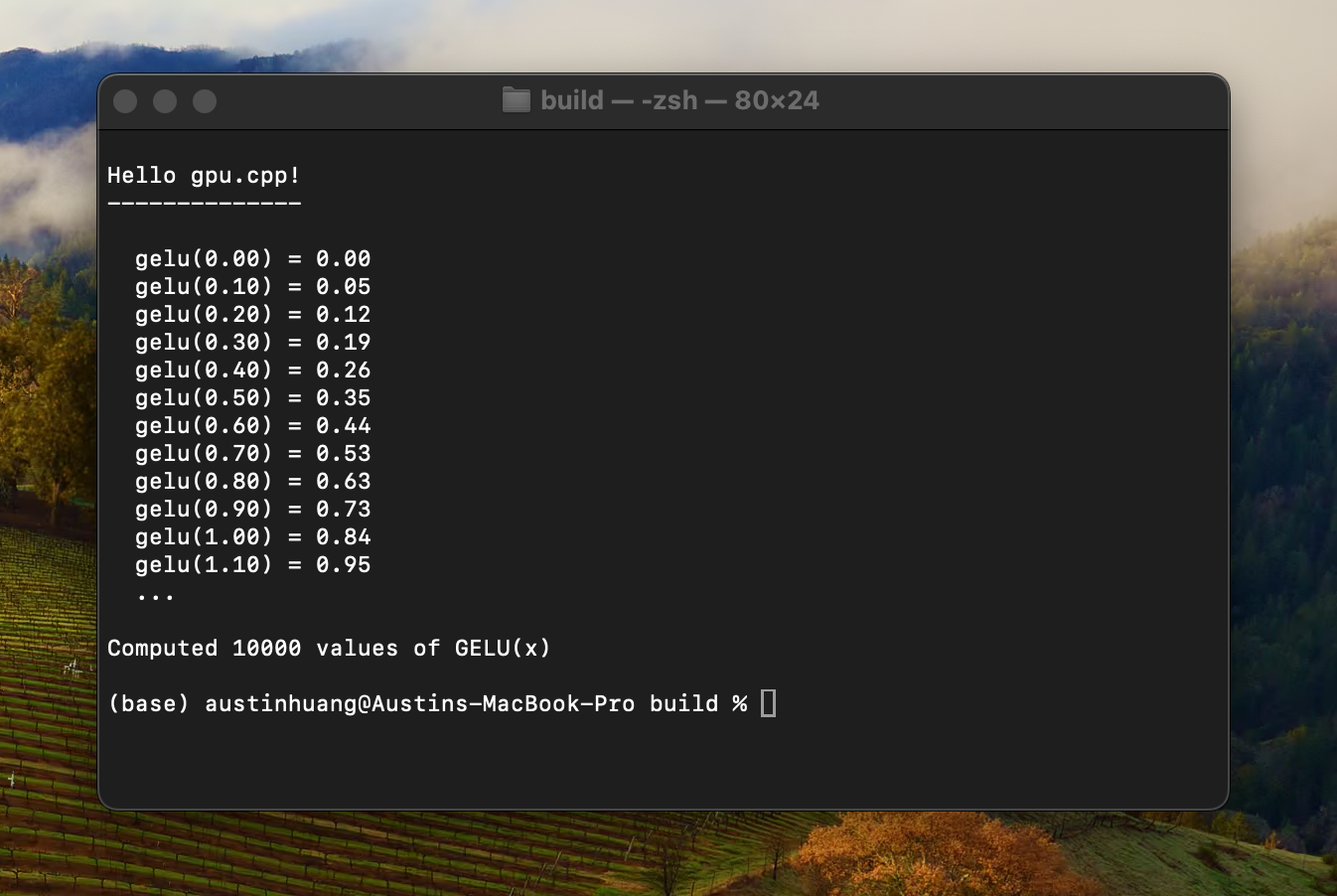
Hello World gpu.cpp
GELU Kernel
Device (GPU)
static const char *kGelu = R"(
const GELU_SCALING_FACTOR: f32 = 0.7978845608028654; // sqrt(2.0 / PI)
@group(0) @binding(0) var<storage, read_write> inp: array<{{precision}}>;
@group(0) @binding(1) var<storage, read_write> out: array<{{precision}}>;
@compute @workgroup_size({{workgroupSize}})
fn main(
@builtin(global_invocation_id) GlobalInvocationID: vec3<u32>) {
let i: u32 = GlobalInvocationID.x;
if (i < arrayLength(&inp)) {
let x: f32 = inp[i];
out[i] = select(0.5 * x * (1.0 + tanh(GELU_SCALING_FACTOR
* (x + .044715 * x * x * x))), x, x > 10.0);
}
}
)";
Host (CPU)
#include <array>
#include <cstdio>
#include <future>
#include "gpu.h"
using namespace gpu;
int main(int argc, char **argv) {
Context ctx = createContext();
static constexpr size_t N = 10000;
std::array<float, N> inputArr, outputArr;
for (int i = 0; i < N; ++i) {
inputArr[i] = static_cast<float>(i) / 10.0; // dummy input data
}
Tensor input = createTensor(ctx, Shape{N}, kf32, inputArr.data());
Tensor output = createTensor(ctx, Shape{N}, kf32);
std::promise<void> promise;
std::future<void> future = promise.get_future();
Kernel op = createKernel(ctx, {kGelu, /* 1-D workgroup size */ 256, kf32},
Bindings{input, output},
/* number of workgroups */ {cdiv(N, 256), 1, 1});
dispatchKernel(ctx, op, promise);
wait(ctx, future);
toCPU(ctx, output, outputArr.data(), sizeof(outputArr));
for (int i = 0; i < 16; ++i) {
printf(" gelu(%.2f) = %.2f\n", inputArr[i], outputArr[i]);
}
return 0;
}
const GELU_SCALING_FACTOR: f32 = 0.7978845608028654;
@group(0) @binding(0) var<storage, read_write> inp: array<{{precision}}>;
@group(0) @binding(1) var<storage, read_write> out: array<{{precision}}>;
@compute @workgroup_size({{workgroupSize}})
fn main(
@builtin(global_invocation_id) GlobalInvocationID: vec3<u32>) {
let i: u32 = GlobalInvocationID.x;
if (i < arrayLength(&inp)) {
let x: f32 = inp[i];
out[i] = select(0.5 * x * (1.0 + tanh(GELU_SCALING_FACTOR
* (x + .044715 * x * x * x))), x, x > 10.0);
}
}
Types - Resources
-
Context- a handle to the state of resources for interacting with the GPU device. -
Tensor- a buffer of data on the GPU which can be bound to aKernel. -
Any simple C++ struct can also be bound to a
Kernel. -
Kernel- a GPU (WGSL) program and its associated GPU buffer bindings hat can be dispatched to the GPU.
Ahead-of-Time Resource Allocation
-
createContext()- constructs a reference to the GPU deviceContext. -
createTensor()- acquires a contiguous buffer on the GPUTensor. -
createKernel()- constructs aKernel, taking as input the shader code and the tensor resources to bind.
Functions
-
dispatchKernel()- asynchronously dispatch aKernelto the GPU for computation. -
wait()- blocks until the GPU computation is complete. -
toCPU()- moves data from the GPU to the CPU. -
toGPU()- moves data from the CPU to the GPU. This is a synchronous operation that blocks until the data is copied.
Hello World (GELU Kernel)
Device (GPU)
static const char *kGelu = R"(
const GELU_SCALING_FACTOR: f32 = 0.7978845608028654; // sqrt(2.0 / PI)
@group(0) @binding(0) var<storage, read_write> inp: array<{{precision}}>;
@group(0) @binding(1) var<storage, read_write> out: array<{{precision}}>;
@compute @workgroup_size({{workgroupSize}})
fn main(
@builtin(global_invocation_id) GlobalInvocationID: vec3<u32>) {
let i: u32 = GlobalInvocationID.x;
if (i < arrayLength(&inp)) {
let x: f32 = inp[i];
out[i] = select(0.5 * x * (1.0 + tanh(GELU_SCALING_FACTOR
* (x + .044715 * x * x * x))), x, x > 10.0);
}
}
)";
Host (CPU)
#include <array>
#include <cstdio>
#include <future>
#include "gpu.h"
using namespace gpu;
int main(int argc, char **argv) {
Context ctx = createContext();
static constexpr size_t N = 10000;
std::array<float, N> inputArr, outputArr;
for (int i = 0; i < N; ++i) {
inputArr[i] = static_cast<float>(i) / 10.0; // dummy input data
}
Tensor input = createTensor(ctx, Shape{N}, kf32, inputArr.data());
Tensor output = createTensor(ctx, Shape{N}, kf32);
std::promise<void> promise;
std::future<void> future = promise.get_future();
Kernel op = createKernel(ctx, {kGelu, /* 1-D workgroup size */ 256, kf32},
Bindings{input, output},
/* number of workgroups */ {cdiv(N, 256), 1, 1});
dispatchKernel(ctx, op, promise);
wait(ctx, future);
toCPU(ctx, output, outputArr.data(), sizeof(outputArr));
for (int i = 0; i < 16; ++i) {
printf(" gelu(%.2f) = %.2f\n", inputArr[i], outputArr[i]);
}
return 0;
}
Gelu CPU / Host Code
#include <array>
#include <cstdio>
#include <future>
#include "gpu.h"
using namespace gpu;
...
gpu.h gives us access to the library API in the
gpu namespace.
Gelu CPU / Host Code
#include <array>
#include <cstdio>
#include <future>
#include "gpu.h"
using namespace gpu;
int main(int argc, char **argv) {
Context ctx = createContext();
static constexpr size_t N = 10000;
std::array<float, N> inputArr, outputArr;
for (int i = 0; i < N; ++i) {
inputArr[i] = static_cast<float>(i) / 10.0; // dummy input data
}
Tensor input = createTensor(ctx, Shape{N}, kf32, inputArr.data());
Tensor output = createTensor(ctx, Shape{N}, kf32);
std::promise<void> promise;
std::future<void> future = promise.get_future();
Kernel op = createKernel(ctx, {kGelu, /* 1-D workgroup size */ 256, kf32},
Bindings{input, output},
/* number of workgroups */ {cdiv(N, 256), 1, 1});
dispatchKernel(ctx, op, promise);
wait(ctx, future);
toCPU(ctx, output, outputArr.data(), sizeof(outputArr));
for (int i = 0; i < 16; ++i) {
printf(" gelu(%.2f) = %.2f\n", inputArr[i], outputArr[i]);
}
return 0;
}
Dawn WebGPU Implementation build ~ 5-10 minutes
What does PyTorch do? Provide shared libraries => from 10 minutes to 1 second builds!

const G: f32 = 9.81;
const dt: f32 = 0.03;
@group(0) @binding(0) var<storage, read_write> theta1: array<f32>;
@group(0) @binding(1) var<storage, read_write> theta2: array<f32>;
@group(0) @binding(2) var<storage, read_write> thetaVel1: array<f32>;
@group(0) @binding(3) var<storage, read_write> thetaVel2: array<f32>;
@group(0) @binding(4) var<storage, read_write> length: array<f32>;
@group(0) @binding(5) var<storage, read_write> pos: array<f32>; // x1, y1 for each pendulum
@compute @workgroup_size({{workgroupSize}})
fn main(@builtin(global_invocation_id) global_id : vec3<u32>) {
let idx = global_id.x;
if (idx >= arrayLength(&theta1)) {
return;
}
let l = length[idx];
// Update angular velocities and angles for theta1
let accel1 = -(G / l) * sin(theta1[idx]);
thetaVel1[idx] += accel1 * dt;
theta1[idx] += thetaVel1[idx] * dt;
// Update angular velocities and angles for theta2
let accel2 = -(G / l) * sin(theta2[idx]);
thetaVel2[idx] += accel2 * dt;
theta2[idx] += thetaVel2[idx] * dt;
// Calculate new positions based on updated angles
pos[4 * idx] = l * sin(theta1[idx]); // x1
pos[4 * idx + 1] = -l * cos(theta1[idx]); // y1
let l_total = 2 * l; // Assuming the second pendulum extends from the end of the first
pos[4 * idx + 2] = pos[4 * idx] + l * sin(theta2[idx]); // x2
pos[4 * idx + 3] = pos[4 * idx + 1] - l * cos(theta2[idx]); // y2
}
static constexpr size_t N = 1000;
Context ctx = createContext();
// Host-side data
std::array theta1Arr, theta2Arr, v1Arr, v2Arr, lengthArr;
std::fill(v1Arr.begin(), v1Arr.end(), 0.0);
std::fill(v2Arr.begin(), v2Arr.end(), 0.0);
for (size_t i = 0; i < N; ++i) {
theta1Arr[i] = 3.14159 / 2 + i * 3.14159 / 16 / N;
theta2Arr[i] = 3.14159 / 2 + i * 3.14159 / 16 / N - 0.1;
lengthArr[i] = 1.0 - i * 0.5 / N;
}
// GPU buffers
Tensor theta1 = createTensor(ctx, Shape{N}, kf32, theta1Arr.data());
Tensor theta2 = createTensor(ctx, Shape{N}, kf32, theta2Arr.data());
Tensor vel1 = createTensor(ctx, Shape{N}, kf32, v1Arr.data());
Tensor vel2 = createTensor(ctx, Shape{N}, kf32, v2Arr.data());
Tensor length = createTensor(ctx, Shape{N}, kf32, lengthArr.data());
std::array posArr; // x, y outputs for each pendulum
std::string screen(80 * 40, ' ');
Tensor pos = createTensor(ctx, Shape{N * 4}, kf32);
// Prepare computation
KernelCode kernel{kUpdateSim, 256, kf32};
printf("WGSL code: %s\n", kernel.data.c_str());
Kernel update = createKernel(
ctx, kernel, Bindings{theta1, theta2, vel1, vel2, length, pos},
/* nWorkgroups */ cdiv({N, 1, 1}, kernel.workgroupSize));
while (true) {
auto start = std::chrono::high_resolution_clock::now();
std::promise promise;
std::future future = promise.get_future();
dispatchKernel(ctx, update, promise);
wait(ctx, future);
toCPU(ctx, pos, posArr.data(), sizeof(posArr));
auto end = std::chrono::high_resolution_clock::now();
std::chrono::duration elapsed = end - start;
rasterize(posArr.data(), N * 2, 2.0, 2.0, screen, 80, 40);
printf("\033[1;1H" // reset cursor
"# simulations: %lu\n%s",
N, screen.c_str());
resetCommandBuffer(ctx.device, update); // Prepare kernel command
// buffer for nxt iteration
std::this_thread::sleep_for(std::chrono::milliseconds(8) - elapsed);
}
ShaderTUI
Goal: Check we can express optimization strategies of [CUDA Matmul Kernel: a Worklog](https://siboehm.com/articles/22/CUDA-MMM)?
... but we can optionally target the browser with WebAssembly + WebGPU!

WebAssembly + WebGPU Browser Builds
WebAssembly + WebGPU Browser Builds
x
FastHTML